이번에는 파이썬 웹크롤링 방법2 시간으로 방법1과는 좀 다른 방식을 소개하겠다. 아직 '파이썬 웹 크롤링 방법 1'을 보지 않은 분들은 한번 읽어보고 와 주시기 바란다.
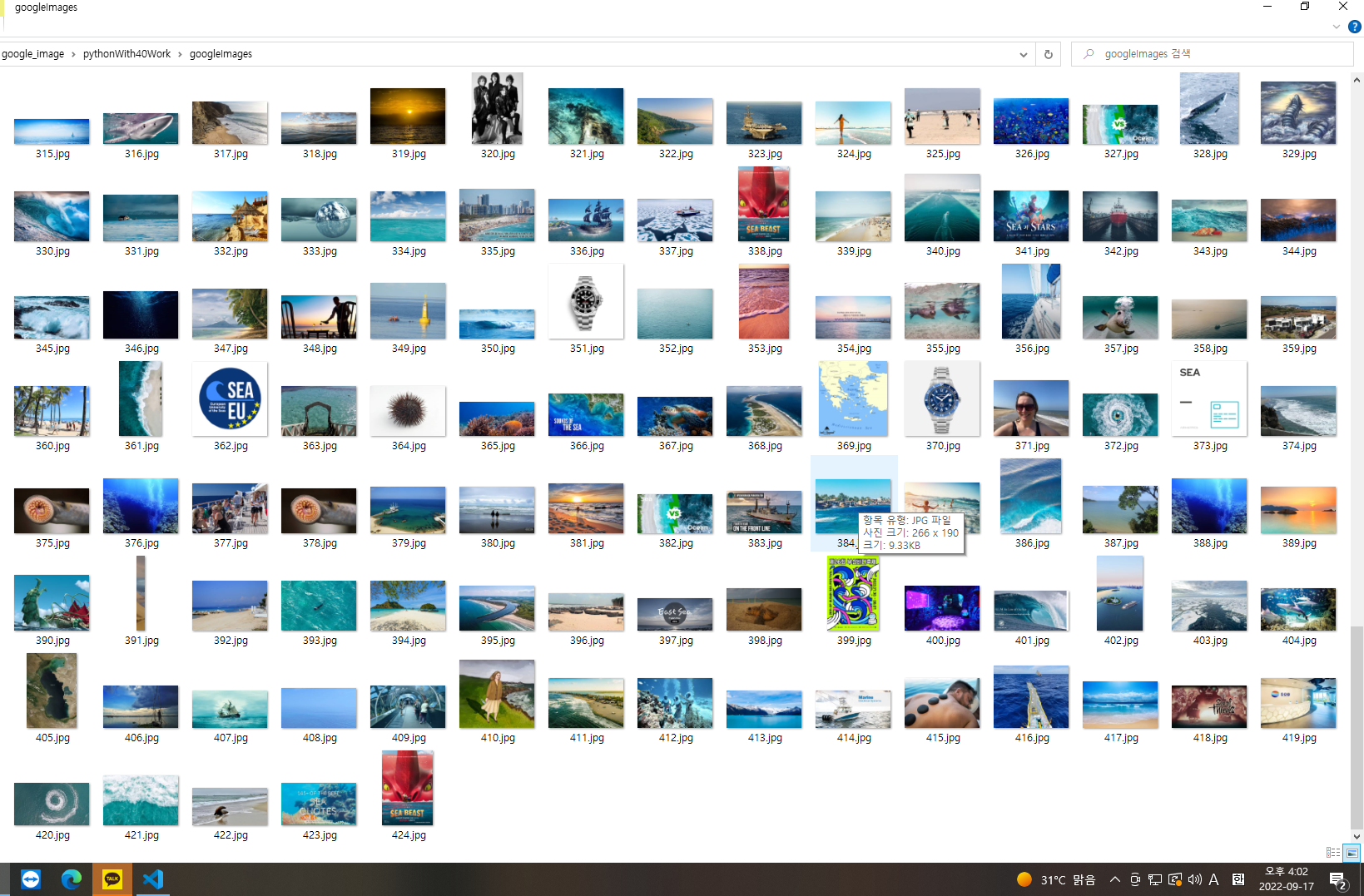
방법1이 추출한 이미지를 한장씩 따로 따로 저장하는 방법이라면 방법2는 추출한 이미지 전체의 주소 링크를 저장하고 이미지 추출이 끝나면 한꺼번에 이미지를 다운 받는 형식이다.
이미지를 다운 받기 위한 selenium 과 크롬 드라이버등은 이미 설치가 되어 있는 것으로 간주하고 시작하겠다. 아직 selenium 과 크롬 드라이버가 설치가 되지 않은 분은 '파이썬 웹 크롤링 방법 1'의 앞부분을 보고 설치해 주기 바란다.
1. 구글 검색창의 CSS 선택자 복사하기

2. 검색창에 다운받기 원하는 이미지의 이름 넣어 검색하기

검색창에 'sea'라는 글자를 넣고 엔터키를 누른다.
elem.send_keys("sea")
elem.send_keys(Keys.RETURN)
3. '결과 더 보기' 버튼 찾아서 눌러주기
'body' 태그를 찾아 elem 이란 변수에 넣어준다. body안에 많은 이미지들이 나타나면 키보드의 'page Down' 키를 반복해서 눌러 준다. 화면의 제일 아래 부분에 이르면 '결과 더보기' 버튼이 있다. 웹 크롤링에서는 이 '결과 더 보기' 버튼을 클릭해 줘야 다음 검색 이미지들이 나타난다. 결과 더 보기' 버튼의 CSS 선택자를 복사해서 find_element_by_css_selector() 함수의 인수로 넣어 주고 클릭 한다.

4.크롤링한 이미지를 모두 찾아 확인하기
이미지의 갯수를 세기 위한 links 배열을 선언하고 이미지들의 CSS 선택자를 images 변수에 넣어준다.
각각의 이미지 CSS 선택자를 보면
#islrg > div.islrc > div:nth-child(700) > a.wXeWr.islib.nfEiy > div.bRMDJf.islir > img,
#islrg > div.islrc > div:nth-child(701) > a.wXeWr.islib.nfEiy > div.bRMDJf.islir > img,
#islrg > div.islrc > div:nth-child(702) > a.wXeWr.islib.nfEiy > div.bRMDJf.islir > img,
등으로 되어 있는 것을 알 수 있는데 이때 div:nth-child(702) 부분을 div 로 변경해 주면 모든 이미지를 선택할 수 있다. 이 과정을 반복하고 그 이미지의 링크를 모두 리스트로 만든다.

'SW 배움터 > 파이썬 업무 자동화' 카테고리의 다른 글
| VS code 파이썬 상태 표시줄 고급팁 (0) | 2022.09.21 |
|---|---|
| 파이썬 웹 크롤링 스킬1 (0) | 2022.09.18 |
| 파이썬 웹 크롤링 방법 1 (0) | 2022.09.16 |
| 파이썬 업무 자동화 3편 : 엑셀 주무르기2 (0) | 2021.10.27 |
| 파이썬 업무 자동화 2편 : 엑셀 주무르기1 (0) | 2021.10.26 |