파이썬으로 웹 크롤링 하는 방법들은 많이 알려져 있는데 그 방법들이 중구난방이라 그 방법들을 따라 해서 이미지를 다운 받는 것이 쉽지만은 않다. 이번 시간에는 웹 크롤링하는 방법들을 단계별로 나누어서 처음 웹 크롤링을 하는 사람이라도 쉽게 따라 할 수 있도록 설명해 보겠다. 일단 컴퓨터에 최신 버전의 파이썬 프로그램이 설치되어 있고 vs code를 사용할 수 있는 환경이라고 가정한다. 두 프로그램이 설치되어 있지 않다면 설치하고 시작하기 바란다.
<가장 일반적으로 인터넷 사이트의 이미지를 다운로드 하는 방법>
1.파이썬 웹 크롤링 파일 만들기
탐색기에 파이썬 웹 크롤링 파일을 저장할 폴더를 하나 만든다. 그리고 vs code 상단 메뉴바에서 '파일' -> '폴더 열기'를 선택하고 그 안에 파이썬 파일을 하나 만든다.
2. selenium 설치
selenium은 웹을 제어하기 위해 제작된 라이브러리 인데 vs code 코드 터미널에서 코드 한줄로 쉽게 설치 할 수 있다. vs code 코드 터미널에 'pip install selenium'이라고 입력하고 엔터키를 누른다.
3. 크롬 드라이버 설치
크롬 드라이버를 설치하기 전에 자신의 컴퓨터에 설치되어 있는 크롬 브라우저의 버전을 알아야 된다. 크롬 주소창에 'chrome://version'이라고 입력해 보자. 첫줄에 나오는 '105.0.5195.125' 숫자가 크롬 버전이다. 이 숫자를 잘 기억해 두자.

이제 https://chromedriver.chromium.org/downloads 사이트에 가서 자신의 크롬 버전과 가장 유사한 버전의 드라이버를 다운 받는다. 버전이 일치하면 좋지만 일치하는 버전이 없을 경우에는 가장 유사한 버전을 다운받아도 된다. 다운 받은 크롬 드라이버를 파이썬 코드를 저장할 폴드에 같이 넣어 둔다.
이제 vs code 코드 터미널에 'pip install webdriver-manager'을 입력하고 크롬 웹 드라이버를 설치한다.
4. 크롬에서 구글 홈페이지를 열고 구글 검색 창에 특정 단어를 입력해 이미지 검색
'강아지'를 입력하고 검색한다. 다른 그림을 검색하고 싶은 분은 다른 단어를 입력한다.

'이미지' 버튼을 클릭해 강아지 이미지들만 나오게 한다.

'도구' 버튼을 클릭해 특정한 옵션을 찾아보자.

도구 버튼을 누르면 3가지 옵션 사항이 나오는데 이중 '상업 및 기타 라이센스' 사항을 선택한다. 이 옵션을 선택하면 이미지들을 상업적인 용도로 사용해도 아무 이상이 없는 이미지들만 나열해 준다. 여기서 브라우저 주소창에 나오는 문자열을 모두 복사해서 저장하자. 이 문자열을 vs code에 입력해서 여기까지 자동으로 오게 할 것이다.
from selenium import webdriver
import time
import urllib.request

5. 첫번째 그림을 클릭하는 코드 작성
이제 첫번째 그림을 클릭하는 코드를 작성해 보자. 먼저 첫번째 나오는 그림을 클릭해 본다.

우측에 첫번째 그림이 크게 확대되어 나타나는데 이때 'F12'를 눌러 '개발자 도구'에 들어 가자. 개발자 도구에 이 페이지를 나타나게 하는 html 코들들이 보인다. 개발자 도구 좌상단의 좌측 위로 향하는 화살표 아이콘을 클릭하고 확대된 첫 그림을 클릭해 보자. 그러면 개발자 도구에 그 그림에 대한 html 코드가 어느것인지 하이라트표시로 구분해 준다.
이 하이라이트 된 부분에 마우스를 갖다대고 마우스 우클릭을 해 보자. 'Copy - > Copy selector' 를 선택한다. 그러면 이 그림에 대한 CSS 선택자를 복사하게 되는 것이다. 첫번째 그림의 CSS 선택자를 driver.find_element_by_css-selector 함수에 넣고 firstImage 변수에 저장한다. 그리고 이 그림을 클릭한다.

6. 선택한 이미지를 저장하는 코드 작성
이제 확대된 그림을 보자. 우리가 수작업으로 이 이미지를 다운 받기 위해서는 이 이미지 위에 마우스를 가져다 두고 우클릭을 해서 '다른 이름으로 그림 저장'이란 항목을 클릭해서 이미지를 저장하게 된다. 그리고 '>'버튼을 클릭해서 다음 그림으로 넘어가고 다음 그림에서 위의 과정을 반복하게 된다. 우리는 이 반복되는 과정을 프로그램으로 작성해서 쉽게 그림을 다운받게 하려고 한다.
큰그림의 CSS 선택자 코드를 복사해서 이것을 driver.find_element_by_css-selector 함수에 넣고 image변수에 저장한다.

그림을 다운 받으려면 실제 이 이미지가 있는 웹 주소가 필요한데 이 주소는 <img> 태그의 src 속성에 들어 있다. image.get_attribute('src')를 이용하여 이 그림이 있는 웹 주소를 imageSrc 변수에 저장한다. 그리고 그림을 저장하는 함수 urllib.request.urlretrieve(그림 주소, 그림을 저장할 경로와 파일명)을 적어 준다. 그림 주소에는 변수 imageSrc를 사용하고, puppy_image.jpg라는 이름으로 그림을 저장한다.
7. 다음 이미지로 이동하는 코드 작성
확대된 그림이 다음 그림으로 넘어가기 위해서는 '>' 버튼을 클릭해야 한다. '>'버튼의 CSS 선택자를 구해보자. 이때 주의할 점이 하나 있는데 클릭 기능을 하는 <a>태그의 CSS 선택자 코드를 복사해야 한다는 것이다. <a> 태그가 아닌 다른 태그를 복사하면 다음 그림으로 넘어가지 않으므로 주의해야 한다. 이 CSS 선택자 코드를 driver.find_element_by_css-selector 함수에 전달하고, 다음 그림으로 넘어가기 위해 nextButton 변수에 저장한다. 그리고 nextButton.click() 으로 다음 그림으로 넘어간다.

8. 검색한 이미지 30개 다운받는 코드 작성
이제 위에서 작성한 그림 하나씩 저장하는 코드를 반복해서 실행하면 그림을 무수히 다운 받을 수 있는 것이다.
9. 예외 처리 코드까지 작성해서 완벽한 코드 작성
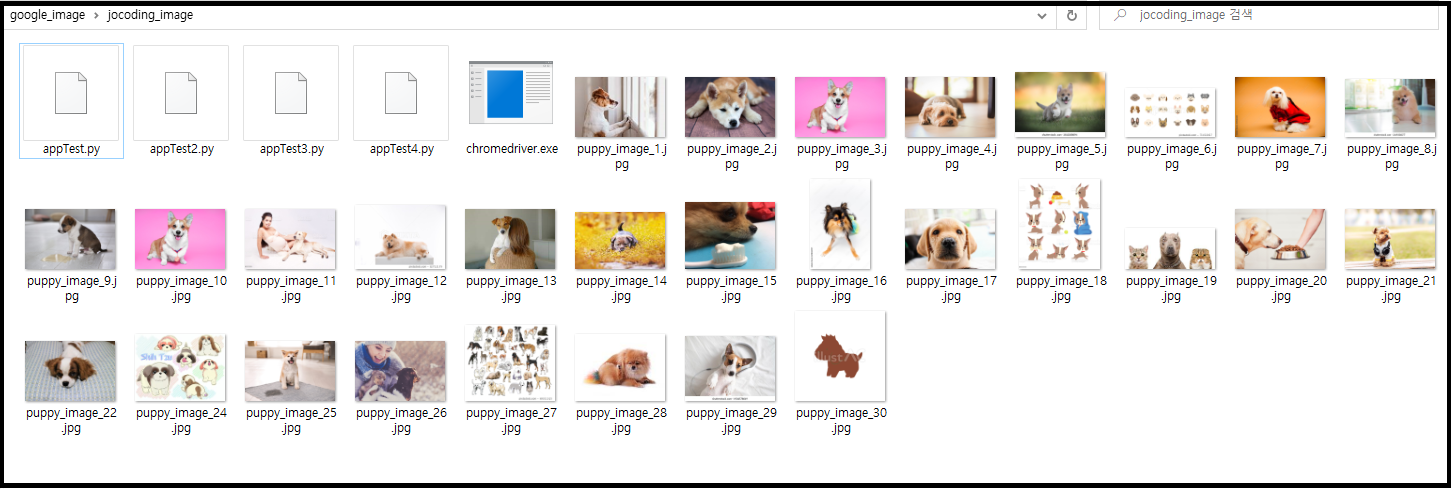
30개의 강아지 그림이 지정한 폴더에 저장되었다. 웹 크롤링이라는 것이 쉬운듯 하면서도 상당히 까다로운 작업이지만 한단계 한단계 차근히 따라가면 누구나 성공할 수 있을 것이다.

'SW 배움터 > 파이썬 업무 자동화' 카테고리의 다른 글
| 파이썬 웹 크롤링 스킬1 (0) | 2022.09.18 |
|---|---|
| 파이썬 웹 크롤링 방법 2 (0) | 2022.09.17 |
| 파이썬 업무 자동화 3편 : 엑셀 주무르기2 (0) | 2021.10.27 |
| 파이썬 업무 자동화 2편 : 엑셀 주무르기1 (0) | 2021.10.26 |
| 파이썬 업무 자동화 1편 : 파이썬으로 폴더 생성 & 제거, 파일 삭제까지 (0) | 2021.10.05 |